A good movie to watch
This blog post deals with the incredibly common task of interpreting a language and extracting its sentiment. Humans are obviously very good at this: if I tell you a story or read some article, you understand its meaning; if I tell you a joke or I’m sarcastic, you get it. Computers… not so much…
But for every difficult task there is obviously a big prize at the end. Think about how much unexploited data there is in textual resources. Virtually every industry can benefit from Natural Language Processing (NLP): from healthcare to finance, from ads to traveling.
But let us start with small steps. The main goal here is rather simple to state: can Deep Learning classify bad or good movies based on their reviews? In order to tackle this problem there are various dataset that one can use. For example, IMDB and Rotten Tomatoes have a lot of reviews that could be used, however their reviews are written by many different people and therefore both the text and the grading might be too heterogeneous. For this reason I decided to approach the problem from a different angle and use the reviews written by a single person: the famous critic Roger Ebert. Clearly does not eliminate the problem but it might reveal some new interesting side of Roger Ebert.
Data
Ebert has been an incredibly prolific reviewer: nearly 50 years as a critic writer with thousands of reviews under the belt. All his reviews (and many others) are available on https://www.rogerebert.com for free. Unfortunately there is no API to access them so I had to gently scrap the website and I made the code available on my repo.
The fields useful for this projects are: the year of publication, the review, and the rating. Overall these fit in a easily manageable dataset of 50 MB.
EDA
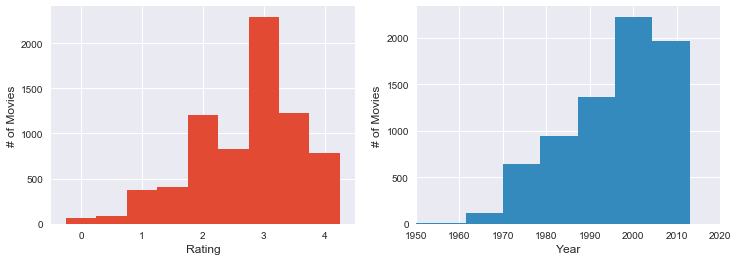
Let us start our EDA by considering the two numerical attributes we have: ratings and year. Before looking at the data one can expect various distribution for these quantities. For example, one can imagine that the rating is distributed uniformly (unlikely), that it peaks at high or low rating, or most likely that it peaks somewhere in the middle. Regarding the year, we already know that there are no reviews after 2013, so the distribution will be truncated.
What does the data say? First of all the distribution of ratings is not what I was expecting. In particular the distribution looks somewhat Poissonian but there is a high number of movies with 3 stars. It seems like Ebert had a sort of psychological anchor there: not sure about the rating? give it a 3!
A more interesting quantity that can be derived from the text is the length of the review. The distribution of length of Ebert’s reviews follows very nicely a log-normal distribution. This happens both if you consider the length defined either as the number of words or the number of sentences in the review. Take a look.
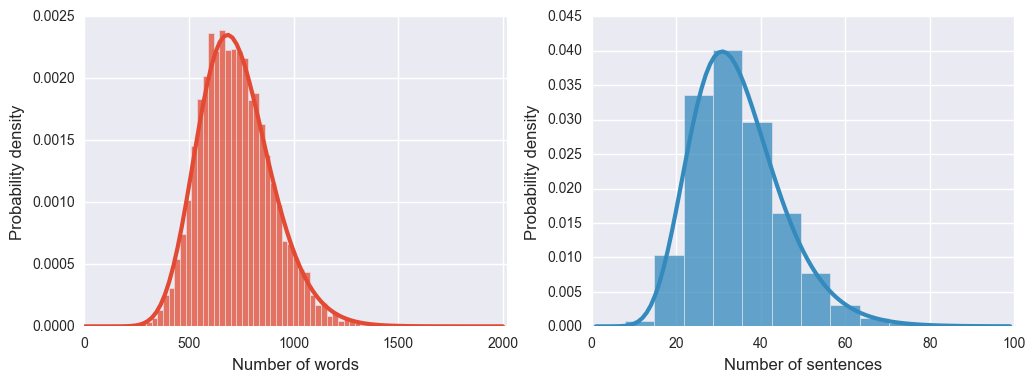
This quite surprising fact is not unique of Ebert’s style but is instead a generic human behavior connected somehow with natural language (information theory?). For those interested you can read more about the occurrence of the log-normal distribution on this Wikipedia entry.
NLP in Python
To be finished…
GitHub Repo
The code for the analysis is available on my GitHub repo if you are interested. Enjoy!